



pytorch深度学习环境配置
编辑pytorch深度学习环境配置
在 PyTorch 官网上有如下安装对照表,同时也有历史版本安装对照表:
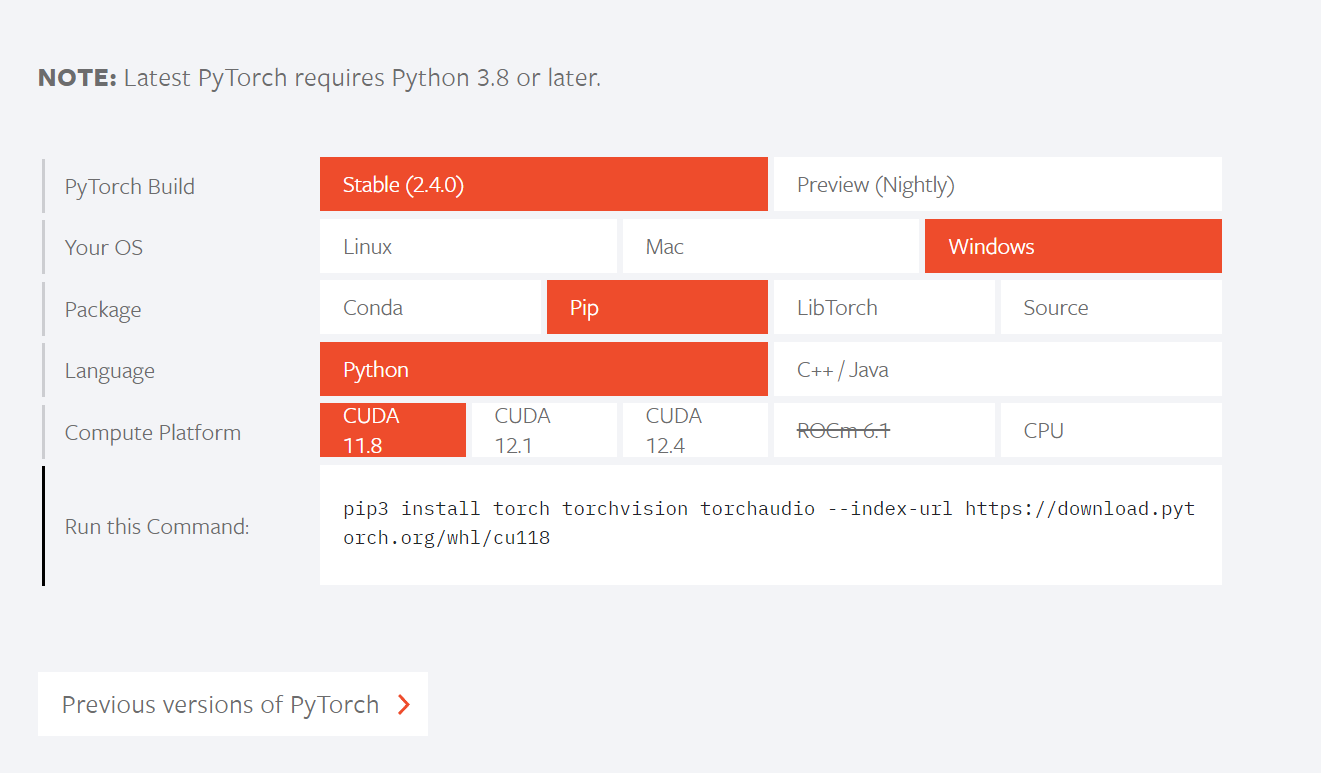
在配置 GPU 加速版本的 Pytorch 深度学习环境中,我们常碰到如下概念,利用 GPT 进行整理:
-
显卡驱动:显卡驱动程序是操作系统和 GPU 之间的桥梁,负责管理 GPU 硬件与计算任务的交互。在深度学习中,安装最新的显卡驱动非常重要,因为它能确保 CUDA 和深度学习框架正确运行,并充分发挥 GPU 的计算能力。
-
CUDA(Compute Unified Device Architecture):由 NVIDIA 开发的并行计算平台和编程模型,允许开发者利用 GPU 的强大计算能力来加速计算任务。CUDA 通过提供扩展的 C/C++ 语言库,使得普通程序员无需直接操作底层 GPU 代码也能进行并行计算。它是 GPU 加速深度学习模型训练的基础。
-
CUDA Toolkit:CUDA Toolkit 是 NVIDIA 提供的开发工具包,包含编译器(
nvcc)、库(如 cuBLAS、cuFFT、cuDNN 等),以及调试、优化和性能分析工具。它使开发者可以为 GPU 编写和优化代码,利用 CUDA 加速应用程序。Toolkit 中的核心组件支持编译、运行和优化 CUDA 程序。 -
cuDNN(CUDA Deep Neural Network library):这是 NVIDIA 提供的用于深度神经网络加速的 GPU 加速库,特别优化了卷积、池化、归一化等深度学习中常见的操作。cuDNN 与主流的深度学习框架(如 TensorFlow 和 PyTorch)集成,用于提升网络的训练和推理性能。
-
PyTorch:一个开源的深度学习框架,支持动态计算图和灵活的模型开发,适合研究和实验性开发。PyTorch 提供了易用的 API,用户可以在 Python 中快速实现和调试深度学习模型。它对 GPU 支持良好,且使用 cuDNN 和 CUDA 实现了 GPU 加速。
-
TensorFlow:由 Google 开发的开源深度学习框架,广泛用于大规模机器学习任务。TensorFlow 支持静态计算图,适合生产环境中的高效计算。它有强大的模型训练和部署工具,支持分布式计算,并且与 CUDA 和 cuDNN 集成,以利用 GPU 进行加速。TensorFlow 也提供了高级接口(如 Keras)以简化开发过程。
在一台全新的电脑上进行环境配置,有在宿主环境直接配置和安装 conda 等虚拟环境后在虚拟环境配置两种途径,下面的流程图表示了两种安装方式的区别。在宿主环境安装可查看此链接进行配置,本文推荐使用第二种方式。

主要配置步骤:
1. 配置显卡驱动(必须)
方法一:宿主环境:CUDA,cuDNN(可选)
方法二:conda虚拟环境:配置 cudatoolkit(必须)
与在宿主环境中配置相比,在虚拟环境中不需要配置 CUDA Toolkits 和 cuDNN 步骤是因为执行如下指令时:
conda install pytorch torchvision torchaudio cudatoolkit=xx.x -c pytorch
CUDA Toolkit:如果只是使用 PyTorch 而不开发 CUDA 应用程序,安装 PyTorch 时自动安装的 cudatoolkit 省略这一步。PyTorch 自带的 cudatoolkit已经包含了 cuDNN。
显卡驱动安装
显卡驱动下载:GeForce® 驱动程序
宿主机CUDA Toolkit 配置
如果本机配备独立显卡,且安装显卡驱动后,可以在终端运行 nvidia-smi, 查看驱动信息,我恰好有不同 CPU 架构的设备,其操作有所不同。
- amd64(
x86_64) 架构:实验室 4060 电脑
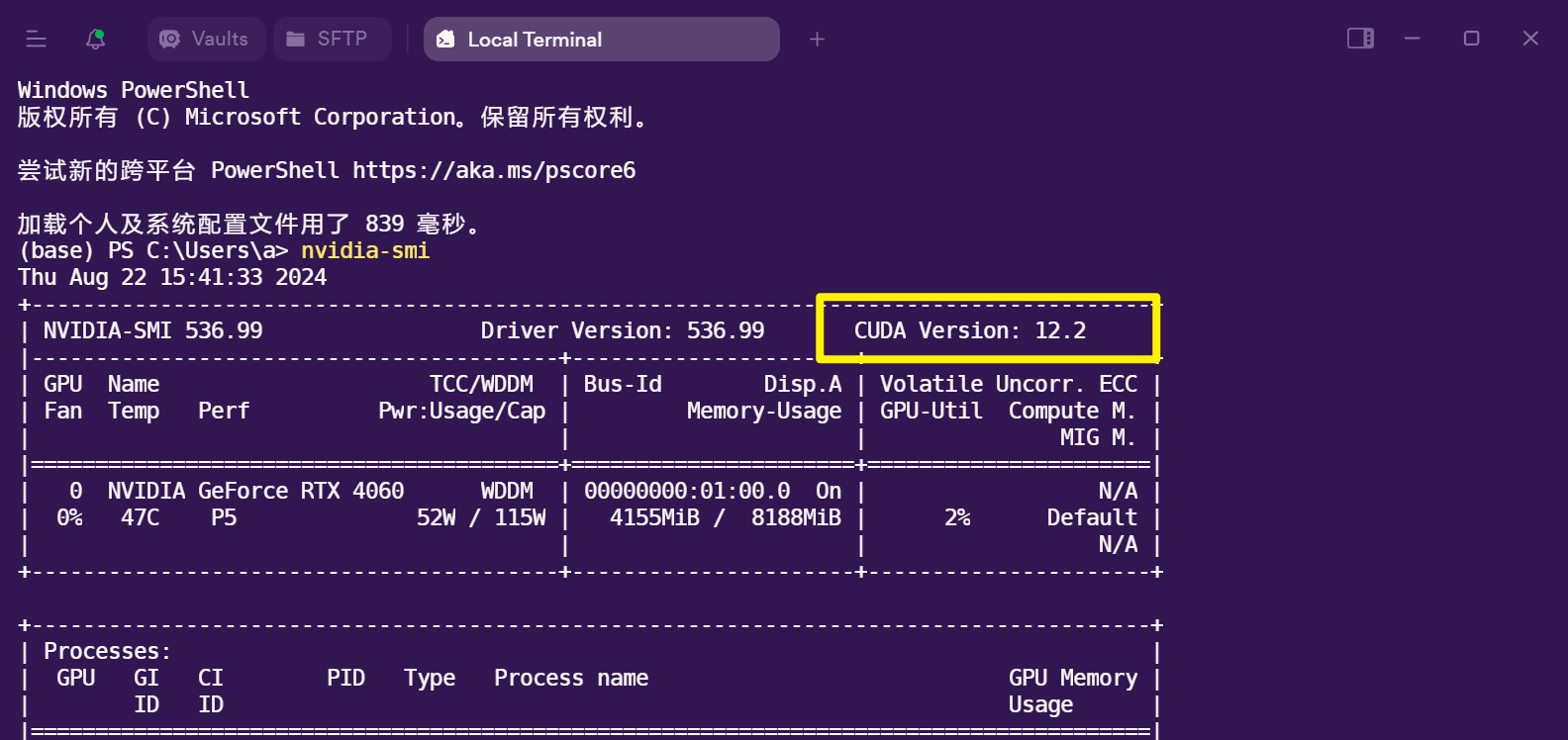
黄框表示我们当前安装的显卡驱动支持的最高 CUDA 运行时 (runtime) 版本,我们可以安装使用不高于此版本的CUDA 程序或工具。
- arm64(
AArch64)架构:Jeston Xavier NX 开发板
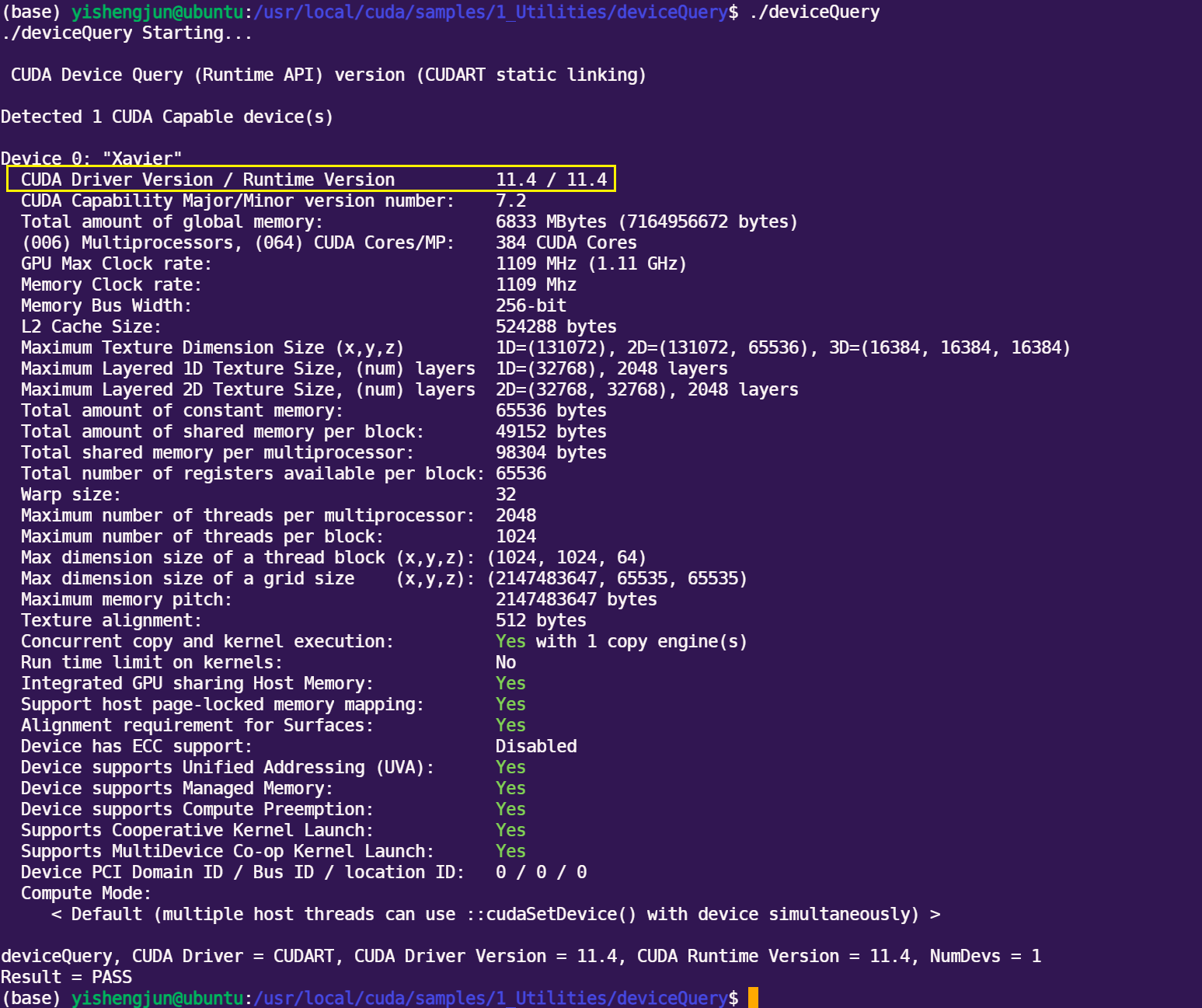
开发板属于 AArch64 架构,与个人 PC 上常见的 X86 架构不同,且由于 Jeston 是显存和物理内存共用,不能通过 nvidia-smi 查看显卡信息,需要执行如下命令才能查看:
cd /usr/local/cuda/samples/1_Utilities//deviceQuery/
sudo make
./deviceQuery
CUDA Toolkit 安装链接,依据主机的系统和架构进行选择,如果电脑的 CPU 为英特尔或者 AMD 的,架构一般选择 x86_64 即可。

cudatoolkit 版本
需要先区分以下两个概念:
CUDA : 这是指通过显卡驱动安装的 CUDA 版本。可以通过 nvidia-smi 命令查看系统中当前安装的 CUDA 版本。
cudatoolkit: 是NVIDIA CUDA 工具包的一个精简版本,专为在 Conda 环境中使用而设计,其为 python 环境中的 GPU 加速计算提供必要的组件。适用于 PyTorch、TensorFlow 等框架。
CUDA 版本兼容性:
- 较新的 CUDA 版本通常向后兼容旧 GPU
- 但新 GPU(如 Ampere 架构)需要较新的 CUDA 版本才能充分发挥性能
cudatoolkit其与系统CUDA的关系:
cudatoolkit可以与系统级CUDA共存- 通常使用系统级CUDA驱动,但运行时库来自
cudatoolkit
# 指定版本安装
$ conda install cudatoolkit=11.2
conda install pytorch torchvision torchaudio cudatoolkit=11.3 -c pytorch
该命令安装了指定版本的 PyTorch,同时也安装了与该版本兼容的 cudatoolkit。这个 cudatoolkit 是一个已编译好的 CUDA 库,它会在运行时被 PyTorch 使用,而不依赖于系统全局的 CUDA 安装。同时 torch 也会自动安装与指定版本的 PyTorch 兼容的 cuDNN。
这里 pytorch 和 cudatoolkit 版本对应关系:pytorch各版本对照
torch 、torchvision、python 对照表
| torch | torchvision | Python |
|---|---|---|
main / nightly | main / nightly | >=3.8, <=3.12 |
2.3 | 0.18 | >=3.8, <=3.12 |
2.2 | 0.17 | >=3.8, <=3.11 |
2.1 | 0.16 | >=3.8, <=3.11 |
2.0 | 0.15 | >=3.8, <=3.11 |
1.13 | 0.14 | >=3.7.2, <=3.10 |
1.12 | 0.13 | >=3.7, <=3.10 |
1.11 | 0.12 | >=3.7, <=3.10 |
1.10 | 0.11 | >=3.6, <=3.9 |
1.9 | 0.10 | >=3.6, <=3.9 |
1.8 | 0.9 | >=3.6, <=3.9 |
1.7 | 0.8 | >=3.6, <=3.9 |
1.6 | 0.7 | >=3.6, <=3.8 |
1.5 | 0.6 | >=3.5, <=3.8 |
1.4 | 0.5 | ==2.7, >=3.5, <=3.8 |
1.3 | 0.4.2 0.4.3 | ==2.7, >=3.5, <=3.7 |
1.2 | 0.4.1 | ==2.7, >=3.5, <=3.7 |
1.1 | 0.3 | ==2.7, >=3.5, <=3.7 |
<=1.0 | 0.2 | ==2.7, >=3.5, <=3.7 |
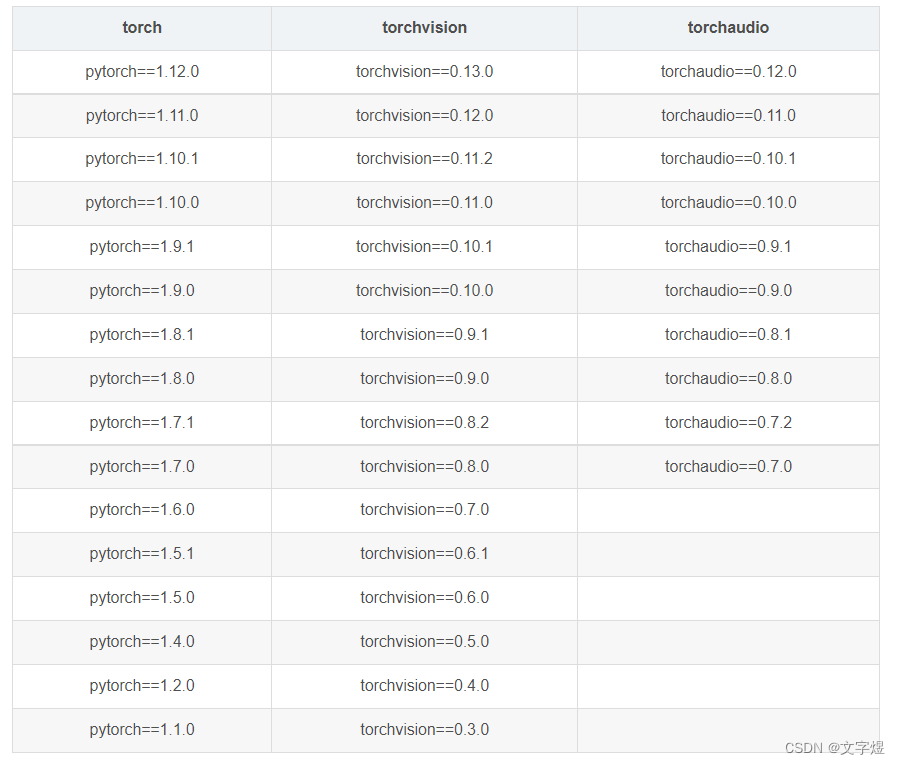
Linux 可直接安装下列版本
# CUDA 11.8
conda install pytorch==2.1.2 torchvision==0.16.2 torchaudio==2.1.2 pytorch-cuda=11.8 -c pytorch -c nvidia
# CUDA 12.1
conda install pytorch==2.1.2 torchvision==0.16.2 torchaudio==2.1.2 pytorch-cuda=12.1 -c pytorch -c nvidia
# CPU Only
conda install pytorch==2.1.2 torchvision==0.16.2 torchaudio==2.1.2 cpuonly -c pytorch
安装完成后运行如下代码检查 CUDA 是否可用
import torch # 如果pytorch安装成功即可导入
print(torch.cuda.is_available()) # 查看CUDA是否可用
print(torch.cuda.device_count()) # 查看可用的CUDA数量
print(torch.version.cuda) # 查看CUDA的版本号

- 0
- 0
-
分享